В прошлый раз мы обсудили, как улучшить рекомендации на базе исторического контекста пользователя. Сегодня посмотрим, как авторы статьи обучали модель DreamRec и генерировали рекомендации.
Уйти от negative-сэмплинга
Негативы нужны, чтобы объекты не коллапсировали в одну точку. В DreamRec оптимизация вариационной нижней оценки сводится к минимизации KL-дивергенции. Происходящее сближение распределений не даёт объектам коллапсировать.
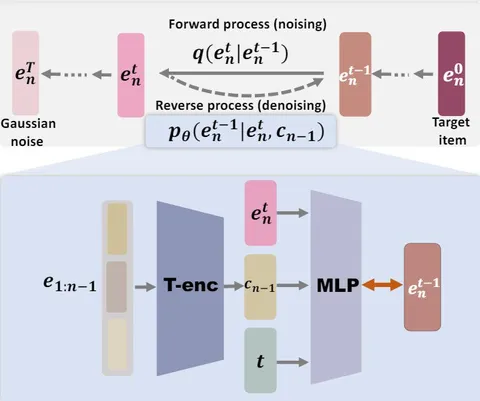
Оба распределения в дивергенции нормальны, поэтому ошибка сводится к средней квадратичной ошибке между шумами. В постановке предсказывается таргет сэмпл, а мат. ожидания оптимизируются по Монте-Карло. В итоге loss сводится к оптимизации среднеквадратичной ошибки. Авторы не говорят, как генерируют таргет сэмпл, скромно называя свою архитектуру MLP (рис. 2).
Обучение
Датасет перегоняется в эмбеддинги, мы агрегируем историю, трансформером в единый вектор и с вероятностью 1/10 подменяем его обучаемым эмбеддингом. Это повышает генеративные способности модели и позволяет ей отвечать даже пользователям без истории.
Сэмплируем момент времени, шум и в сгенерированный момент зашумляем таргет. В прямой марковской цепочке переходы известны, поэтому скипаем лишние шаги и записываем зашумлённый эмбеддинг. Затем MLP-модель предсказывает таргет в нулевой момент, мы считаем среднюю квадратичную ошибку, дифференцируем и обновляем параметры MLP.
Генерация
Таргетный эмбеддинг генерируется из стандартного нормального распределения. Агрегируем историю, добавляем шум и сэмплируем эмбеддинг в следующий, т. е. предыдущий момент времени. Для холодных пользователей кроме диффузии, обусловленной контекстом, используется диффузия с обученным на претрейне эмбеддингом. Усредняем, избавляемся от шума — и «оракул» готов! Если его не существует в реальности — рекомендуем ближайших соседей.
@RecSysChannel
Разбор подготовил