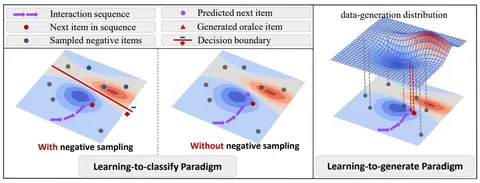
Поговорим о моделях, генерирующих следующий айтем на основе предыдущих взаимодействий пользователя — это может быть трек в плейлисте, видео, товар и т. д. По словам авторов статьи, SR обычно работает в парадигме learning-to-classify — получает позитивы, выполняет сэмплинг негативов, дополняет ими выборку и обучается. При этом неизвестно, видел ли юзер полученные айтемы и считает ли их нерелевантными. Альтернатива — использовать диффузию и перейти к learning-to-generate.
Пользователь примерно понимает, что хочет найти. Этот гипотетический айтем авторы называют oracle. Не факт, что он существует — тогда человек выберет что-то близкое из предложенных вариантов. Но именно «оракула» должна сгенерировать Guided Diffusion-модель.
Как это сделать
В прямом процессе на обучение берётся известный таргет и постепенно зашумляется. Незначительный гауссовский шум добавляется на каждом шаге (их тысячи), в итоге приходя к стандартному нормальному шуму. В обратном процессе мы избавляемся от шума, обуславливаясь на исторический контекст пользователя, закодированный трансформером в обобщающий вектор. Это позволяет выйти за рамки конкретных айтемов и сэмплировать абстрактное предложение.
Авторы описывают три подхода к диффузии:
— DDPM — оптимизация нижней вариационной оценки логарифмов правдоподобия наблюдаемых таргетов, которая сводится к оптимизации дивергенции Кульбака — Лейблера. Основной метод, использующийся в статье.
— Непосредственное рассмотрение двух марковских цепочек — если расписать score-функцию, этот подход эквивалентен певрому.
— Проведение аналогии между СДУ и диффузионной моделью актуально для генеративных моделей, т. к. позволяет получить логарифм нулевого распределения на таргетах и замерять им качество на этапе инфиренса.
Эффективность подхода проверяли экспериментами и сравнениями с другими моделями. Код и данные лежат тут. Во второй части мы подробнее расскажем о генерации и обучении.
@RecSysChannel
Разбор подготовил