Высокая гетерогенность фичей мешает использовать трансформеры в рекомендательных системах. Ресёрчеры из Google поделились статьёй, где предложили решение: модифицированный attention-слой позволил уловить связи, важные для предсказания итогового таргета. В тестах подход показал рост ключевых метрик (клики, покупки) — например, +0,4% по сравнению с DCN.
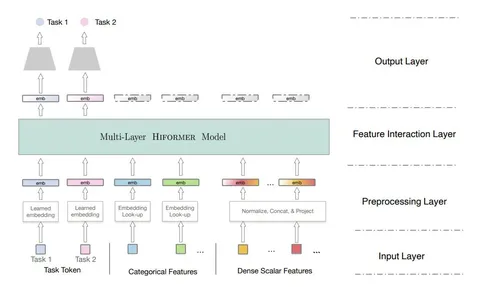
Подготовка фичей
На вход модели подаются cat- и dense-фичи. Cat-фичи обрабатываются стандартно (для них строятся обучаемые эмбеддинги), а с dense-фичами поступают чуть сложнее: их нормализуют, конкатенируют, применяют линейное преобразование, а потом сплитуют по D — внутренней размерности трансформера. Так фичей становится меньше.
Heterogeneous Attention Layer
Здесь матрицы query, key и value (QKV) считают отдельно для каждой фичи. Чтобы вычислить итоговый вектор для токена, вектора со всех голов, отвечающих фичам, конкатенируются и умножаются на матрицы.
Затем данные идут на Feed Forward-слой (FFN) с активацией GELU. Полученный вектор и будет выходом attention-слоя. Количество операций по сравнению с обычным трансформером не растёт, увеличивается лишь число параметров.
Hiformer
Чтобы уловить сложные взаимодействия, систему снова модифицируют — создают одну большую матрицу фичей. Затем конкатенируют все фичи каждой головы, умножают их на матрицу и получают модифицированные вектора. Благодаря этому получается выявить новые закономерности и связи, в т. ч. между composite-фичами и task-эмбеддингами.
Оптимизация
С большой матрицей трансформер становится тяжёлым с точки зрения latency — его нужно оптимизировать. Авторы используют низкоранговое разложение и прунинг последнего слоя. В первом случаем мы уменьшаем сложность за счёт разложения большой матрицы на две матрицы меньшего ранга.
Прунинг выполняется на последнем слое, где можно обучать таргет по task-эмбеддингам. Обычно итоговых задач намного меньше, чем фичей, что снижает сложность матричных умножений.
@RecSysChannel
Разбор подготовила