Статья о любопытном подходе к EBR (Embedding-based retrieval) для учёта нескольких интересов пользователя. Авторы не просто растят diversity и fairness, но и утверждают, что увеличивают общее качество. В статье это показано на примере SASRec, но в теории подход сработает для любых трансформеров над историей пользователя.
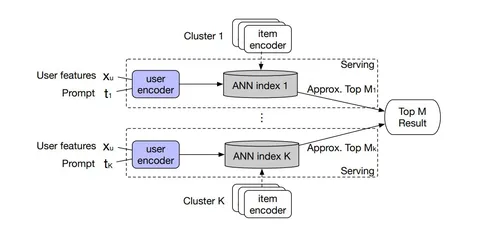
Суть — в кластеризации исходного множества айтемов на подмножества, в которые на этапе retrieval ходят отдельными kNN. При этом в каждом кластере обучают отдельный таск и рассматривают задачу в целом как multi-tasking learning (MTL).
Это решает проблему классического обучения на всем множестве айтемов с семплированием негативов, где одновременно происходит дискриминация простых и сложных негативов, что отрицательно влияет на качество, поскольку модель имеет дело с конфликтующими задачами.
В экспериментах авторы проводили кластеризацию через K-means на Word2Vec, но также можно использовать уже имеющееся in-house разбиение документов на категории.
Три подхода к MTL
В статье описано три варианта реализации multi-tasking learning. Первый подход — наивный, где на вход добавляется ещё один обучаемый вектор. Работает это не очень хорошо — у модели не получается выучить взаимодействия между фичами.
Вторая реализация оказалась удачной — покомпонентное умножение обучаемого вектора на каждый из эмбеддингов истории пользователя. Это немного похоже на attention, хотя есть и различия — умножение, вероятно, даёт более общую модель.
Третий подход — MoE (Mixture of Experts), где используется несколько специализированных сетей — экспертов — для решения одной задачи. Он работает лучше, чем наивный multi-tasking, но хуже, чем покомпонентное умножение, и получается дороже по времени обучения.
По нашему мнению, подход с разбиением на кластеры будет полезен не только в сценариях с рекомендациями на всём множестве айтемов, но и для конкретных срезов — то есть рекомендаций или поиска внутри категорий.
@RecSysChannel
Разбор подготовил