Разбираем статью о real-time dialogue-модели Moshi, которая, в отличие от предыдущих диалоговых систем, объединяет в одной архитектуре три компонента: ASR (распознавание речи), LLM (языковая модель) и TTS (синтез речи). Такая схема позволяет воспринимать речь и генерировать ответ одновременно. Управление тем, когда говорить и когда слушать, реализовано через специальный управляющий токен. (Даже я не всегда так умею — прим. автора).
Архитектура модели состоит из четырёх частей, и у всех звучные названия. В этом посте уместим разбор двух первых частей, а в следующем — ещё двух.
Helium
Простая текстовая модель, предсказывающая следующий токен.
Претрейн модели проводился на 2,1 трлн токенов. (Для сравнения: Llama 2 — 1,8 трлн, Llama 3 — 15,6 трлн). Данные собирали, фильтруя CommonCrawl — огромный дамп интернета, где много мусора, но если хорошо почистить, получается неплохой датасет. В итоге датасет состоит из 87,5% CommonCrawl и 12,5% Wikipedia.
После претрейна провели три дополнительных этапа обучения: пост-тренировку, файнтюнинг и инструкционное обучение — чтобы модель лучше справлялась с диалогами. По оценке авторов, Helium сравнима с Llama 2 и первым Mistral, но не дотягивает до Llama 3.
Mimi
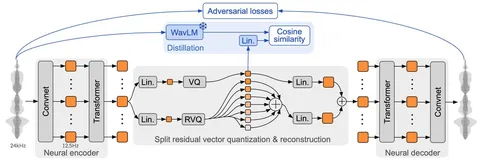
Нейросетевой аудиокодек на основе Residual Vector Quantization (RVQ). Архитектура — стандартный энкодер-декодер, но с интересными деталями: обычно в аудиокодеках используются только свёрточные слои, а тут добавили трансформеры — в конце энкодера и в начале декодера. Это сделало кодек умнее (и тяжелее).
Ещё одно важное отличие Mimi от остальных аудиокодеков — у него довольно маленькая герцовка. Mimi нужно 12,5 векторов, чтобы закодировать секунду аудио. Для сравнения у EnCodec — 75, WavTokenizer — 40. За счёт этого трансформер поверх такого кодека можно учить с бóльшим батчем (в секундах) и быстрее инферить.
Набор лоссов у Moshi примерно такой же, как и у HiFi-GAN-a. Единственное отличие — это то, что авторы убрали L1-loss между STFT-спектрограммами, из-за плохой корреляции с человеческим восприятием. Без него субъективные метрики получались лучше.
Главное ноу-хау Mimi — семантическая дистилляция, которая позволяет получить акустические токены со свойствами семантических.
Акустические токены создаются кодек-моделями вроде Mimi. Из них можно хорошо и качественно восстановить аудиозапись, но они плохо кодируют смысл и плохо связаны между собой. Из-за этого дальнейшей модели (в нашем случае — Moshi) сложно их предсказывать.
Семантические токены делаются SSL-моделями — здесь это WavLM. Эти токены хорошо связаны между собой, они кодируют смысл сказанного в аудиозаписи. Но они не предназначены для того, чтобы восстанавливать из них аудиозапись.
Получается, что нужны акустические токены со свойствами семантических — это то, чего авторы пытались достичь семантической дистилляцией.
Решение — дистиллировать семантические эмбеддинги WavLM в акустические эмбеддинги Mimi. Для этого нужно посчитать косинусное расстояние между эмбеддингами WavLM и Mimi и использовать это как дополнительную компоненту лосса. Есть одна проблема — у моделей разные герцовки: у WavLM — 50, а у Moshi — 12.5, в 4 раза реже. Мы не можем просто посчитать косинусное расстояние между соответствующими эмбеддингами. Чтобы справиться с этим, авторы применили AveragePooling со stride-ом 4 к последовательности эмбеддингов из WavLM и привели обе последовательности к одной частоте — 12,5.
В следующей части разберём главное об устройстве модели Moshi и алгоритма Inner-monologue.
Роман Кайль