Продолжаем разбирать Moshi — диалоговую систему, которая совмещает распознавание, чат-бота и синтез речи в одной модели. В первой части речь шла о LLM Helium и аудиокодеке Mimi. Здесь — о том, как устроена сама Moshi и как работает механизм переключения между «слушать» и «говорить».
Moshi
На следующем этапе авторы хотят научить текстовую LLM Helium аудиомодальности, а конкретно — предсказывать токены от Mimi. Да ещё и так, чтобы модель не потеряла свои LLM-ные знания.
Наша задача — предсказывать матрицу из токенов с размерностями времени на 8 кодеков. Для этого модель Moshi состоит из двух трансформеров: Temporal Transformer и Depth Transformer.
Temporal Transformer — это большой трансформер, проинициализированный весами Helium. Он будет авторегрессивно идти по размерности времени и генерировать эмбеддинг для каждого тика времени. Depth Transformer инициализируется шумом. Его задача — на каждом шаге Temporal Transformer-a закондишениться на сгенерированный эмбеддинг и развернуть его в 8 Mimi-токенов.
Учиться вся эта конструкция будет в три этапа. Тут опускаем много подробностей, но идея примерно такая:
1. Учимся на огромном, шумном audio-only датасете. На этом этапе моделька познаёт аудиомодальность и пытается соотнести её с текстовой модальностью.
2. Учимся на синтетических диалоговых данных. Здесь модель учиться слушать и слышать одновременно, подстраивается под диалоговый формат (так называемый full-duplex-режим).
3. Тюнимся на более качественном диалоговом датасете. Модель обретает свой голос и выучивает более осознанные диалоговые ответы.
Важнейшая фича Moshi — full-duplex: способность модели одновременно слушать и говорить. С ней диалог получается плавнее и человечнее, в нём могут быть одновременные реплики, перебивания и междометия. Модель достигает режима full-duplex с помощью алгоритма Inner Monologue.
Inner-monologue
Для начала, мы хотим сделать так, чтобы одно и то же слово, представленное в виде текстовых токенов и в виде аудиотокенов, занимало одно и то же количество токенов. Для этого авторы взяли датасет и модель WhisperV3 и сделали алайнмент. То есть для каждого слова в тексте нашли время, когда оно начинает и заканчивает произноситься. После этого авторы взяли специальные паддинг-токены и в текстовой модальности добавили их после каждого слова — столько, чтобы по длине они совпадали с количеством токенов, которое занимает это слово в аудиомодальности.
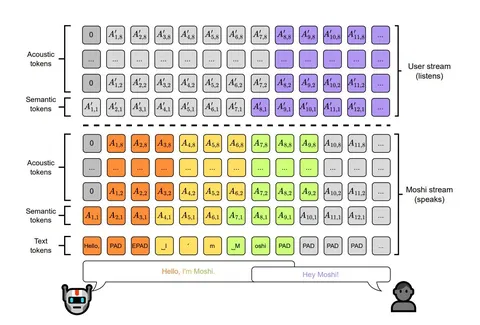
Дальше мы хотим учить модельку на этих данных. Тут полезно посмотреть на картинку.
— Мы хотим, чтобы в каждый момент времени наша моделька работала с тремя стримами информации: аудио, которое произносит пользователь (8 токенов), аудио, которое произносит Moshi (8 токенов), и текст, разбавленный паддингами, который произносит Moshi (1 токен). На картинке они показаны сверху вниз.
— Мы хотим все три стрима подавать на вход к модельке. Соответственно для каждого стрима токенов будет своя матрица эмбеддингов, которые в итоге складываются.
— На выход мы хотим получать только текст и аудио реплик. На картинке — это оранжево-жёлто-зелёные (каждый цвет — отдельное слово) токены. Текст предсказывает линейная голова поверх Temporal Transformer, а для аудиотокенов есть Depth Transformer.
— В такой парадигме моделька учится и инферится.
Moshi вышла 7 месяцев назад и, кажется, уже потихоньку устаревает. Если попользоваться демкой, сначала она приводит в восхищение, но потом становятся заметны косяки: модель говорит глупости, неуместно перебивает, начинает отвечать с большой задержкой. Она ощутимо слабее, чем, например, VoiceMode от OpenAI. Но у ребят подробная статья, много интересных выводов и экспериментов, а также выложенный в открытый доступ кодек. Это довольно большой вклад в область.
Роман Кайль