В прошлой части рассказали о работах на тему шумоподавления в наушниках, теперь переходим к голосовой активации. Сегодня кратко о двух статьях: одна — о визуальном споттере (активация по звуку и видео, но без активационной фразы), вторая — о кастомных keyword spotters.
An Efficient and Streaming Audio Visual Active Speaker Detection System
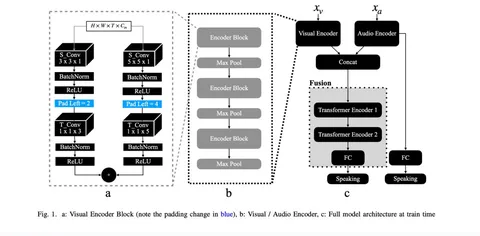
Статья от Apple на тему детекции активного спикера в стриминговом видео с помощью аудио- и видеосигналов. Такая задача уже решается в колонках Amazon и Google. Архитектура построена на двух похоже устроенных энкодерах: аудио- и визуальном. В них используются каузальные свёртки, которые не «заглядывают» в будущее — это важно для стриминга.
После извлечения признаков фреймы выравниваются и объединяются, чтобы для каждого момента времени были и аудио-, и визуальные фичи. Поверх этого авторы обучают трансформер. Трансформеру за счёт использования масок также ограничивали возможность «заглядывать» в будущее.
Ключевое исследование — о том, какие маски использовать в трансформере: сколько контекста из прошлого и будущего ему давать. Контекст из будущего начинает помогать, только если в модель уже подаётся достаточно длинный контекст из прошлого — примерно от 15 фреймов.
По ощущениям, решение довольно зрелое: авторы утверждают, что обучали модель не только на YouTube, но и на внутренних данных.
SLiCK: Exploiting Subsequences for Length-Constrained Keyword Spotting
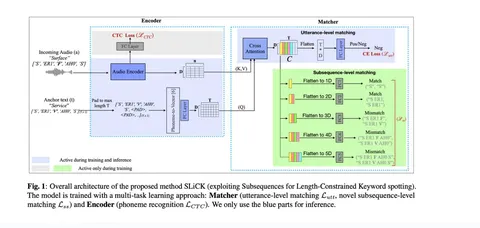
Ещё одна статья — о кастомных keyword-spotters: пользователь задаёт произвольную фразу, на которую должна реагировать модель. На эту тему в последнее время выходит довольно большое количество статей. Для начала GPT-подобная модель превращает текст в последовательность фонем.
Архитектура включает fully connected-слой, который кодирует фонемы в эмбеддинги, и аудиопарсер, который учится по звуку восстанавливать ту же последовательность. Главная особенность работы — продуманные лоссы, которые помогают модели устойчиво обучаться.
Во-первых, аудиомодель учат предсказывать последовательность фонем — это даёт хорошую привязку к произнесённому тексту. Во-вторых, добавляют рантайм-механизм сопоставления между аудио и заданной последовательностью: с помощью cross-attention проверяют, совпадают ли векторы в нужных местах. И в-третьих, делают то же самое, но уже для всех префиксов заданной последовательности. Если на нужной фонеме случается несовпадение — срабатывает сигнал об ошибке.
Если первые два пункта уже встречались ранее, то третий — нововведение этой статьи, которое, судя по результатам, приносит заметный прирост по качеству.
Основной вывод: такой подход с дополнительными лоссами и проверкой совпадений позволяет сильно улучшить точность детекции по сравнению с базовыми моделями. Концепция не совсем новая, но реализация аккуратная и работающая.
В следующей части обзора расскажем о двух LLM для улучшения ASR.
Алексей Рак