На ICLR в этом году было не так много статей на тему аудио, но несколько интересных работ всё же встретились — продолжаем разбирать их в этом и следующих постах.
Сегодня расскажем, как синтетические данные помогают обучать аудиоклассификаторы (Synthio), об универсальной модели, которая по тексту и аудио решает множество задач (Fugatto), и о свежем бенчмарке на понимание сложных аудиозадач — от ритма до аккордов (MMAU).
Synthio: Augmenting Small-Scale Audio Classification Datasets with Synthetic Data
В статье предлагают пайплайн для генерации синтетических аудиоданных с помощью T2A-модели, которая по текстовому описанию создаёт аудио. Её сначала выравнивают на основе предпочтений, используя ограниченное количество размеченных примеров. После этого модель генерирует синтетику, пригодную для задач классификации.
На втором этапе добавляют фильтрацию: оценивают соответствие между текстом и аудио и отбирают качественные пары. Дополнительно текст можно уточить с помощью LLM. На выходе — расширенный синтетический датасет, который даёт прирост точности в разных аудиоклассификационных задачах.
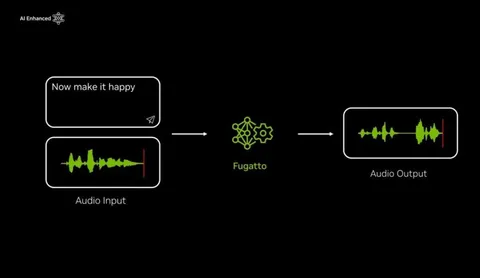
Fugatto 1: Foundational Generative Audio Transformer Opus 1
Fugatto — универсальная аудиомодель, которая по текстовому описанию и/или аудиопримеру решает задачи синтеза речи (TTS), преобразования голоса (VC), генерации аудио по тексту (T2A), шумоподавления и другие. Всё в одной архитектуре.
Модель построена на flow matching — это позволяет отказаться от GAN-дискриминаторов и легче масштабировать обучение. В качестве данных собирают максимально разнообразные открытые датасеты по всем типам задач. Для генерации инструкций, которым должна следовать модель, используют LLM: она пишет код на Python, который вызывает нужный аудиоэффект (например, через библиотеку Pedalboard).
Авторы показывают emergent-эффекты: модель способна выполнять необычные преобразования, которых явно не было в обучении — например, «лающий женский голос» или «мяукание саксофона». Также они демонстрируют, как можно итеративно прогонять сэмплы между A2T- и T2A-моделью, уточняя выходы на каждом шаге.
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Авторы собрали бенчмарк из 10 000 аудиозаданий, вручную размеченных специалистами. Каждое задание состоит из аудио, текстового вопроса и нескольких вариантов ответа. Примеры задач — от понимания какой конкретный звук длится дольше всего на аудио до музыкального анализа: нужно определить аккорд-прогрессию, ритмический рисунок или эмоциональную окраску.
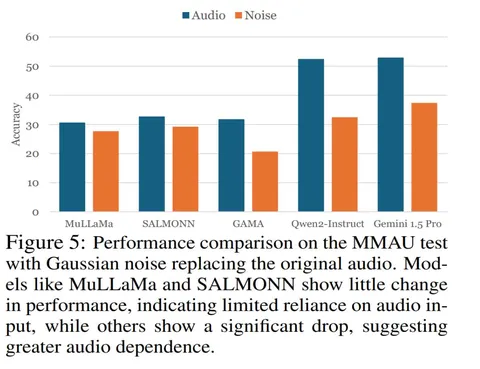
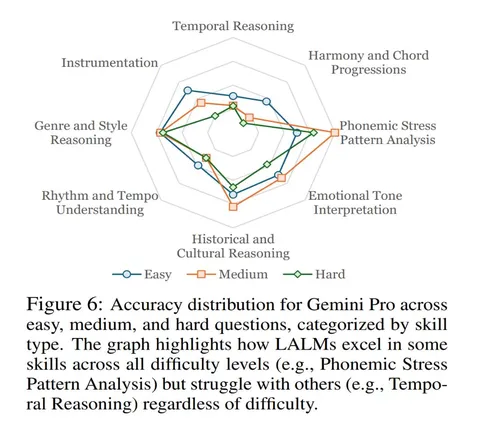
Бенчмарк сложный: требует не просто услышать звук, но и понять его структуру. Некоторые модели (например, MuLaLaMa и SALMONN) почти не теряют точности при замене аудио на шум — значит, не используют сам звук. А вот Gemini 1.5 Pro и Qwen2 действительно извлекают аудиосигнал: при шуме качество падает. Gemini 1.5 Pro лучше всего справляется с задачами фонетического анализа.
MMAU подчёркивает важность реального аудиопонимания: на нём даже сильные мультимодели работают на уровне 59% точности. Из аблейшна авторов следует, что основная доля ошибок приходится на perceptual errors. То есть моделям пока сложно понимать, что именно происходит на записи.
Влад Батаев
#YaICLR