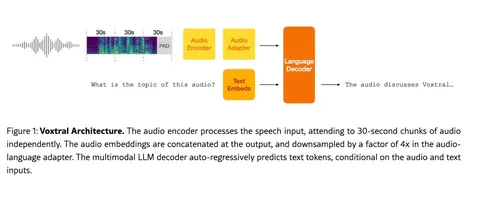
Сегодня разбираем статью об опенсорсной модели Voxtral от Mistral AI. Ключевая идея решения в том, чтобы к уже обученной текстовой LLM «прикрутить» аудио. Для этого используют готовый ASR-энкодер (Whisper) и адаптер, после чего ответы генерирует языковой декодер. Аудио режут на фрагменты по 30 секунд, обрабатывают их энкодером, склеивают эмбеддинги и прореживают в четыре раза в адаптере, уменьшая длину последовательности. На вход декодеру можно подать и текстовые токены, например вопрос или инструкцию.
Есть две версии модели. В составе Mini-версии — аудиоэнкодер на 640 млн параметров, адаптер на 25 млн, текстовые эмбеддинги на 400 млн и декодер на ~3,6 млрд (всего ~4,7 млрд); в Small — аналогичный аудиоэнкодер и адаптер на 52 млн, но уже 670 млн в эмбеддингах и 22,9 млрд в декодере (всего ~24,3 млрд). Контекст аудиоветки — до 32 тысяч токенов, что соответствует примерно 40 минутам звука.
Для предобучения длинное аудио сначала размечают (VAD → транскрипция → диаризация), затем разбивают на пары (Aₙ, Tₙ) и учат на двух паттернах: repetition, где по аудио восстанавливают его транскрипцию, и continuation, где по аудио восстанавливают следующий текст. На первом проходе замораживают аудиоэнкодер и языковой декодер, обучая только адаптер — это заметно помогает в задачах понимания речи, тогда как на чистом ASR почти не сказывается.
Стадия SFT нужна, чтобы модель умела больше, чем просто распознавание речи. Датасет SFT состоит из синтетических примеров. В случае, когда инструкция передается текстом для длинных аудио, транскрипцию из ASR обрабатывает LLM, генерируя пары «вопрос-ответ». Если же инструкция задана в аудио формате, то авторы адаптируют текстовые SFT-датасеты с помощью озвучки инструкций через предобученную TTS-модель.
Есть и стадия RL/DPO-подобного обучения по парам ответов, которая даёт выигрыш в основном на маленькой модели. При этом для задачи ASR на большой модели данный этап даже снижал качество, поэтому в релиз он не вошёл.
Авторы отдельно показывают, что обучение только на interleaved-паттерне портит ASR, а только на ASR-паттерне — не даёт навыков понимания. Смешение двух задач примерно 50/50 даёт хороший баланс распознавания и понимания.
В бенчмарках Voxtral улучшает Whisper (взятый за энкодер) и показывает SOTA среди открытых моделей на части тестов по ASR. В переводе речи и аудиопонимании результаты конкурентны открытым моделям, а по синтетическим мультимодальным тестам на озвученных TTS данных местами уступают проприетарным системам уровня GPT-4o и Gemini. При этом текстовые навыки LLM после добавления аудио практически не страдают.
Влад Батаев