В Ванкувере стартовала конференция ICML, а это значит, что мы — уже по традиции — будем делиться самым интересным с мероприятия. И вот первая подборка постеров, с пылу с жару.
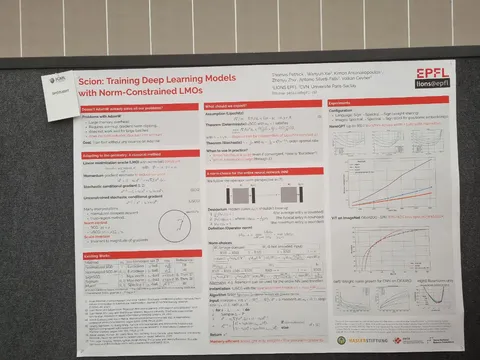
Scion: Training Deep Learning Models with Norm-Constrained LMOs
Самый популярный оптимизатор — AdamW — не делает никаких предположений о геометрии весов модели. Из-за этого во время обучения надо накапливать и хранить статистики градиента. В Scion сразу вводят предположение о норме весов и используют linear minimization oracle для вычисления их апдейта на каждой итерации. Для разных типов слоёв можно (и нужно) использовать разные нормы.
Получаем менее требовательный к памяти алгоритм — не надо хранить первый и второй моменты градиента. Кроме того, оптимальные гиперпараметры переносятся между моделями разных размеров. А главное — Scion находит лучший лосс по сравнению с AdamW и позволяет сократить общее время обучения на 25-40% . Это происходит благодаря большому батчу.
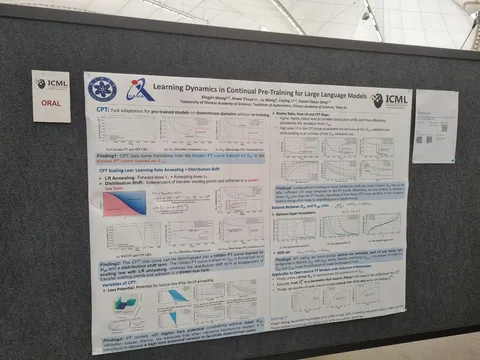
Learning Dynamics in Continual Pre-Training for Large Language Models
Было много постеров о scaling laws. На этом — исследуют динамику дообучения (continual Pre-training), зависимость от lr schedule и от данных. Заметили, что на дообучении лосс сходится к тому же значению, что и при обучении на этом же датасете с нуля. Кроме того, лосс повторяет форму lr scheduler с некоторой задержкой. Опираясь на это, выводят scaling law. Ну а дальше подбирают некоторые оптимальные гиперпараметры обучения.
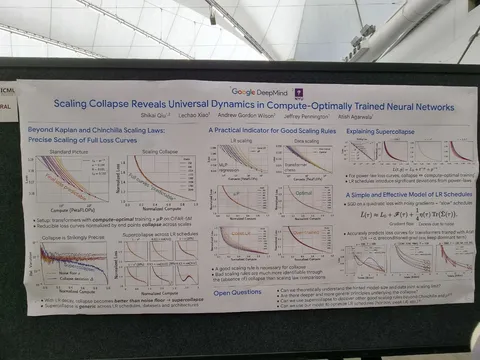
Scaling Collapse Reveals Universal Dynamics in Compute-Optimally Trained Neural Networks
Ещё один интересный постер о scaling law. Здесь показали, что если построить график нормированного лосса (нормируем на финальное значение) от нормированного компьюта (переводим в [0; 1]), то кривые для моделей разных размеров накладываются друг на друга. Причём этот феномен зависит от lr и lr scheduler. Для переобученных моделей кривые будут накладываться с некоторым шумом, а для неоптимальных lr — могут и вовсе расходиться. Также выводят scaling law, который зависит от lr scheduler. Как это можно использовать на практике — пока вопрос открытый.
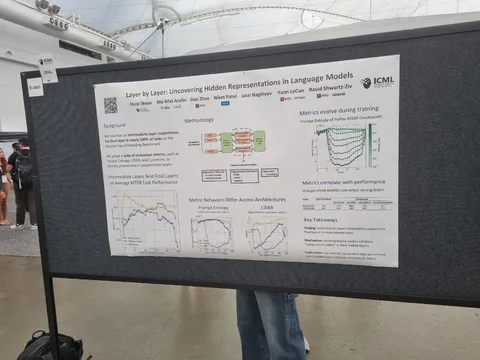
Layer by Layer: Uncovering Hidden Representations in Language Models
Интересный постер об эмбеддингах промежуточных слоёв трансформера. Всегда считалось, что если нужны эмбеддинги для какой-нибудь задачи (например, классификации), то надо просто снять их с последнего слоя, и будет хорошо. А здесь авторы исследовали, насколько хороши эмбеддинги промежуточных слоёв (проверяют на MTEB), и оказалось, что всегда лучше брать какой-то промежуточный. Чтобы узнать, какой именно — считаем метрику prompt entropy для каждого слоя по некоторому набору входных данных. Чем она меньше — тем лучше будут работать эмбеддинги с этого слоя.
Интересным поделился
#YaICML25
Душный NLP