Продолжаем рассказывать о том, что увидели на конференции.
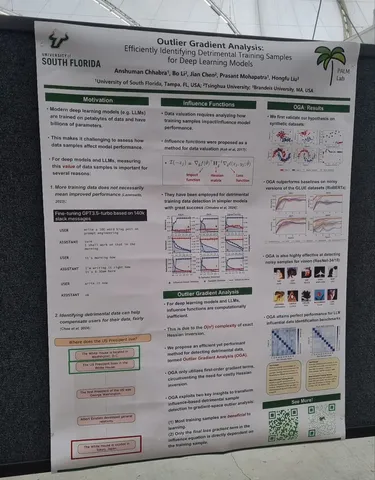
Outlier Gradient Analysis: Efficiently Identifying Detrimental Training Samples for Deep Learning Models
Для нахождения плохих или, наоборот, хороших примеров в датасете часто используют influence function — это некоторый скор, который показывает, насколько сильно изменится лосс, если пример убрать из обучения. Проблема в том, что для вычисления функции надо обращать гессиан по параметрам модели, что вычислительно очень сложно.
В этой статье заметили, что на самом деле можно смотреть только на градиенты модели по примерам, которые мы проверяем. Если они сонаправлены с градиентами по данным из обучения — примеры хорошие, и наоборот. Далее, на основе этого можно применять методы детекции аномалий для нахождения примеров, которые портят обучение, и отфильтровывать их (но можно делать и наоборот — искать хорошие примеры и добавлять их в обучающую выборку). Основное преимущество метода — вычислительная простота; не нужны супердорогие обращения гессиана: только forward и backward pass модели для заданных примеров.
Towards Memorization Estimation: Fast, Formal and Free
Как померить меморизацию посэмплово, запоминала модель пример или нет? Для этого надо обучить модель один раз на данных с этим примером, а потом ещё несколько моделей на данных без него, и померить лосс на примере. Это очень дорого вычислительно. Но можно сделать проще — вычислять лосс на примере несколько раз в течение обучения и посчитать сумму. Если она выше некоторого порога, значит модель не смогла запомнить пример.
Где это можно применять? Для фильтрации данных. Если вдруг модель никак не может выучить какой-то пример, то, вероятно, в нём есть шум (например, неправильное решение математической задачи или неполное условие). Такие примеры можно выкидывать и улучшать точность модели или уменьшать компьют на обучение. Интересная и простая идея, надо проверять, действительно ли она будет работать для LLM (в статье проверяли только на задаче компьютерного зрения, в которой одни и те же данные проходят несколько эпох).
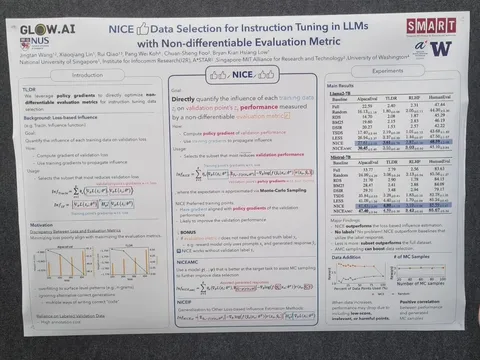
NICE Data Selection for Instruction Tuning in LLMs with Non-differentiable Evaluation Metric
В этой статье снова задаются вопросом, как выбирать такие примеры для обучения, чтобы на валидации получать хорошее качество. Отличие в том, что качество на валидации измеряется не лоссом, а произвольной необязательно дифференцируемой функцией (например, accuracy). В качестве её градиента используют policy gradient.
Jailbreaking LLMs and Agentic Systems: Attacks, Defenses, and Evaluations
На туториале рассказали о защите языковых моделей от нарушения политик элайнмента — например, чтобы модель не выдавала инструкции по созданию опасных веществ или не генерировала дискриминационный контент. Оказалось, что white-box-модели с доступом к весам (например, Llama) до сих пор уязвимы к так называемым token-based-атакам — вставке «мусорных» токенов в промпт. С этим неплохо работают методы поиска инжекта, близкого к кластеру безопасных промптов.
Промпт-инжекты по-прежнему похожи на попытки обмануть не очень внимательного человека, но сейчас работают лучше. Для большинства моделей удаётся подобрать рабочий инжект за 256 попыток («shots»).
Дальше рассказывали о методах защиты. Понятный способ — кластеризовать опасные состояния, добавить состояния отклонения ответа и дообучить модель переходить в них. Однако такой подход снижает качество ответов даже на безобидные вопросы (например, «how to kill python script» — из-за слова kill).
Другой способ — «пошатать» промпты и с помощью majority vote ответов решить, отказаться отвечать или выдать ответ на исходный промпт. При этом иногда ответить может быть приемлемо: например, если инструкция по сборке бомбы нерабочая.
В заключительной части рассказали о взломе агентов. Выяснилось, что там уязвимостей ещё больше, потому что появляется дополнительная возможность дать на вход вредоносный контент, причем его достаточно совсем мало.
Интересное увидели
#YaICML25
Душный NLP