Сегодня у нас краткий обзор PEFT (Parameter-Efficient Fine-Tuning) в визуальных моделях. Разберём три подхода и ключевые статьи в каждом из них.
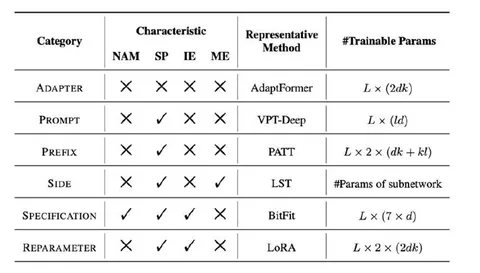
Аддитивные методы
AdaptFormer
Базовый метод в этом классе, который фактически копирует адаптер-тюнинг из LLM. Подразумевает добавление адаптер-блока с понижением, нелинейным преобразованием и повышением размерности.
Обычно адаптер-блоки последовательно добавляют к feed-forward-слоям, а авторы подключают их параллельно — при этом адаптер складывается с результатом feed-forward-слоя с некоторым весом. Этот вес задаётся как гиперпараметр. В LLM его обычно берут больше единицы (например, 4), а для ViT у авторов лучший результат получился при 0,1.
В статье утверждают, что этот метод, применённый к VLM, даёт более высокие результаты по сравнению с prompt tuning, а иногда и с full tuning.
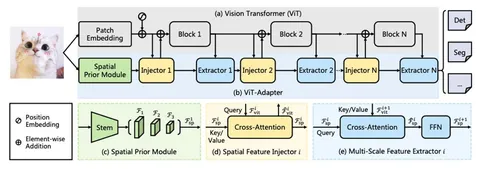
ViT-Adapter
Авторы исходят из того, что CNN лучше извлекают пространственные признаки, поэтому добавляют в ViT адаптер, который объединяет CNN и ViT. Основные компоненты адаптера:
— Spatial prior module — CNN на основе Stem из ResNet (свёртки 3×3 со stride=2 и свёртка 1×1), которая проецирует карты признаков в размерность D. На выходе получается пирамида {F1, F2, F3} из D-мерных карт с разрешениями 1/8, 1/16 и 1/32 от исходного. Эти карты разворачиваются и конкатенируются в один вектор.
— Spatial Feature Injector — компонент, состоящий из n блоков, где i-й блок добавляет пространственную информацию в i-й блок ViT с помощью слоя cross-attention.
— Spatial Feature Extractor — компонент, состоящий из n блоков, где в i-й блок добавляют многоуровневые признаки из i-го блок ViT с помощью: слоя cross-attention, FFN-слоя и skip connection с результатом i-го блока инъектора.
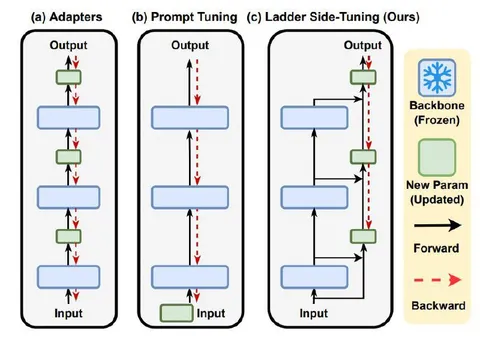
Side Tuning
LST: Ladder Side-Tuning
Side-tuning впервые предложили в LST. Идея в том, что адаптеры и prompt-tuning уменьшают число обучаемых параметров, но не решают проблему памяти, так как требуют полного распространения градиента. В side-tuning выходы адаптеров в исходную архитектуру не попадают напрямую, что экономит ресурсы.
Реализация:
— добавляют несколько блоков-адаптеров, которые представляют собой маленькие трансформеры;
— с каждого трансформерного блока основной модели выход подают на соответствующий адаптер через линейное сжатие размерности. При такой подаче выход трансформерного блока суммируется с результатом предыдущего блока адаптера;
— суммирование происходит с помощью gate-механизма (обычный обучаемый гейт);
— метод можно применять как к декодеру, так и к энкодер-декодер-архитектурам. В ViLT-5 авторы использовали его только на уровне энкодеров-декодеров LLM, но не в самом ViT, так как там выход напрямую передаётся в адаптер для перевода визуальных токенов в языковые.
Эксперименты показали, что использование классических адаптеров вместо трансформерных блоков ухудшает качество, как и замена gate на cross-attention. Для инициализации маленьких трансформеров применяли pruning с матрицей информации Фишера.
Prompt-like-методы
Visual prompt tuning
Метод — буквально обычный Ptune, добавленный в сам ViT. Сравнивали, куда именно добавлять промпты: базовый вариант даёт результат не хуже остальных. Аналогично проверяли, куда подключать «классификационную голову» на выходе ViT, и снова базовый вариант оказался не хуже. Есть несколько вариаций: добавление промптов только в первый слой или deep visual prompt tuning — обучаемые векторы для каждого блока.
CoOp: Context Optimization
Метод, сделанный для CLIP в задачах классификации. Вместо ручного промпта используют обучаемые векторы. В отличие от Ptune, текстовый промпт тут убирается полностью. Метод сам по себе тривиальный, но стал базой для других подходов (например, CLIP-Adapter).
Разбор подготовил
CV Time