Сегодня разбираем статью от исследователей из Yandex Research, появившуюся на arXiv.org в марте 2025 года. Авторы предложили метод дистилляции Scale-wise Distillation (SwD), при котором диффузионная модель не сразу генерирует изображение в полном разрешении, а постепенно повышает его на каждом шаге. Такой подход позволяет ускорить процесс генерации более чем в два раза по сравнению с обычной дистилляцией.
Диффузия на данный момент — ведущая парадигма в области генерации изображений. Но, к сожалению, генерация даже одной картинки может быть довольно долгой. Причина: нужно делать много шагов, каждый из которых считается в фиксированном конечном разрешении и вычислительно затратен.
Проблему попытались решить с помощью scale-wise-генерации: стартовать с одного пикселя и постепенно повышать разрешение, приходя к результату за несколько шагов. Тогда первые шаги идут в низком разрешении и стоят очень дёшево — затраты растут по мере увеличения размера изображения.
Эта парадигма реализована в VAR (Visual Autoregressive Transformer), но кроме scale-wise-генерации, там используется представление изображения в виде дискретных токенов и авторегрессия. Однако дискретное представление изображений приводит к неустранимым ошибкам в представлении картинок и ограничивает максимально достижимое качество.
Отсюда возникла идея вытащить из VAR scale-wise-генерацию и поместить её во фреймворк, сочетающий лучшие стороны обеих парадигм (VAR и диффузии). Метод обучения SwD-подхода основан на известных процедурах дистилляции диффузионных моделей. Но дистилляция в этом случае позволяет не только уменьшить число шагов генерации, но ещё и генерировать при меньших разрешениях.
Интуиция авторов исходит из анализа диффузионного процесса в фурье-пространстве. У естественных картинок амплитуды частот убывают с ростом частоты, а у гауссова шума спектр плоский. Когда мы добавляем шум, высокочастотные компоненты изображения маскируются — сначала самые тонкие, потом всё больше. В итоге на ранних шагах модели остаются только низкие частоты, а детали всё равно «съедаются» шумом.
Это объясняет, почему диффузия хорошо подходит для генерации изображений: она восстанавливает сигнал от грубых низкочастотных структур к высоким частотам и деталям. Однако становится очевидно, что на начальных этапах нет смысла использовать полное разрешение — всё, что модель посчитает, будет уничтожено шумом.
Есть важные нюансы:
— если напрямую увеличивать разрешение шумных латентных представлений, возникает много артефактов, и качество изображения значительно ухудшается. Поэтому лучше сначала увеличить разрешение чистой картинки в низком разрешении, а затем добавить шум;
— важно подобрать такие шаги, чтобы уровень шума подавлял артефакты увеличения разрешения. Расписание шумов имеет критическое значение: в отличие от базовой дистилляции с равномерным расписанием, здесь его следует сдвинуть в сторону более высокого уровня шума, чтобы «погасить» дефекты увеличения разрешения;
— «перезашумить» — не так страшно, как «недозашумить». Если шума будет меньше, чем требует текущий шаг, качество сильно упадёт, и на финальных картинках появятся артефакты.
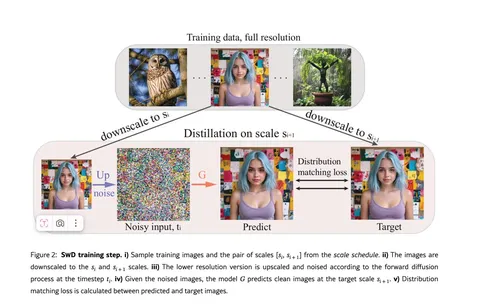
Обучение строится на парах соседних разрешений. Исходное изображение уменьшают до меньшего и до целевого размера. Малоразмерное изображение увеличивают, добавляют шум в соответствии с шагом t и подают в генератор, который предсказывает изображение в целевом разрешении. Функция потерь основана на сопоставлении распределения между предсказанием и целевым изображением (distribution matching).
Отдельно важно, что модель учится на синтетике учителя. Предобученной диффузией генерируют много картинок на основе некоторой выборки пользовательских запросов. Такой подход даёт заметный прирост качества по сравнению с обучением на реальных картинках.
Разбор подготовил
CV Time