Сегодня разберём сразу две статьи о семействе моделей Florence: что такое Florence-2 и как авторы использовали её в VLM.
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Это cемейство VLM-моделей появилось в 2023 году. По сути, это и была VLM, хотя сам термин тогда ещё не вошёл в широкое употребление. Показательно, что в Florence-2 авторы сделали ставку не на архитектуру, а на огромный и качественно собранный датасет FLD-5B.
В основе архитектуры — обычная схема энкодер-декодер-трансформер. Разве что схему VLM авторы нарисовали не так, как принято в 2025-м.
Вся суть статьи в пайплайне обработки данных. Авторы сформулировали множество разных задач в формате «текст на входе — текст на выходе». Так всю разметку можно условно поделить на три группы:
— понимание картинки в целом (classification, captioning, VQA) — семантика;
— умение локализовать объект (object detection, segmentation, referring expression comprehension) — геометрия;
— поиск и детекция объектов по набору признаков (text grounding) — семантика + геометрия.
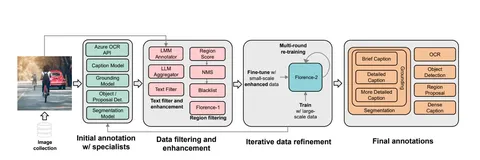
Пайплайн обработки данных, с помощью которого получили обучающий датасет — на первой иллюстрации к посту:
1. первичная аннотация с помощью специализированных моделей (детекторы, OCR, сегментаторы);
2. фильтрация данных той же нейросетью: исправляют ошибки, удаляют ненужные аннотации;
3. итеративный процесс уточнения данных всё той же нейросетью.
FLD-5B состоит из 5 млн аннотаций, 126 млн изображений, 500 млн текстовых аннотаций, 1,3 млн текстовых аннотаций для локализации объекта на изображении и 3,6 млн текстовых аннотаций для поиска и детекции объектов по набору признаков.
Как итог, Florence-2 умеет делать 10+ задач (OCR, detection, segmentation, Caption to Phrase Grounding и др.) и довольно редко галлюцинирует. Однако, в отличие от современных VLM, она не справляется со сложными инстрактами, потому что не училась этому. Да и инстракты может принимать небольшие.
Florence-VL: Enhancing Vision-Language Models with Generative Vision Encoder and Depth-Breadth Fusion
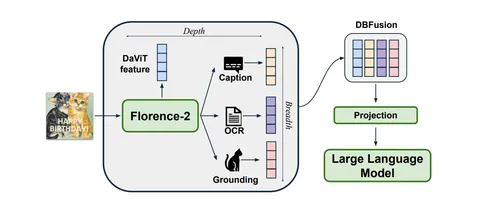
Во второй статье авторы предлагают простую идею — использовать в качестве энкодера в VLM Florence-2. Причина проста: эта модель явно училась на OCR, детекцию и сегментацию, в отличие от CLIP/SigLIP (хотя SigLIP2 уже училась с next token prediction).
Заменить Image Encoder на Florence несложно. Нужно трижды инферить Image Encoder — по одному разу для получения признаков с прицелом на OCR, детекцию и сегментацию. Дальше фичи конкатенируются и пропускаются через projection (DBFusion), чтобы получить желаемое число каналов. Так появилось семейство Florence-VL. Подробнее — на второй иллюстрации к посту.
В результате Florence-VL демонстрирует высокую согласованность визуального энкодера и LLM, превосходя другие модели по 25 критериям. В том числе в задачах распознавания объектов, понимания семантики, распознавания текста и построения диаграмм.
Идея интересная, но, как показало время, не прижилась. Видимо, из-за того, что при таком подходе растёт число операций для получения фичей.
Разбор подготовил
CV Time