Конференция за конференцией — мы на SIGIR 2026!
В эти дни в Мельбурне проходит конференция по исследованиям и разработке информационного поиска. И мы уже там, чтобы посмотреть (и вам показать) интересное, а также представить собственную работу — Gated Bidirectional Linear Attention for Generative Retrieval.
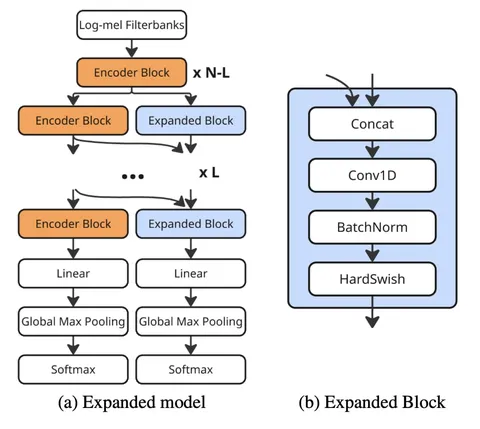
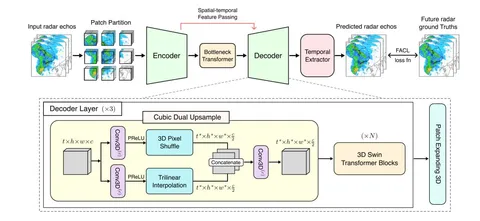
В рекомендательных системах generative retrieval обычно строится по схеме «энкодер–декодер». Энкодер обрабатывает историю взаимодействий пользователя, после чего авторегрессионный декодер генерирует рекомендуемые объекты. В крупных стриминговых сервисах активные пользователи со временем накапливают очень длинные истории. По мере их роста энкодер становится одним из основных узких мест с точки зрения задержки, поскольку вычислительная сложность внимания с softmax квадратично зависит от длины последовательности.
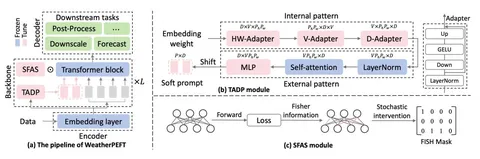
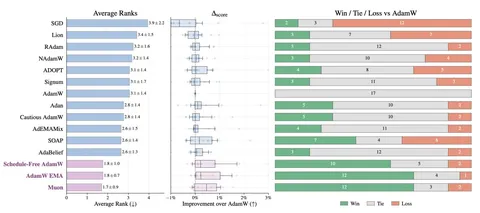
В статье предлагают Gated Bidirectional Linear Attention (GBLA) — слой двунаправленного аттеншена с линейной вычислительной сложностью, который расширяет линейное внимание тремя компонентами: локальным каузальным смешиванием с помощью Conv1D, гейтингом ключей на уровне последовательности для мягкого забывания и выходным слоем gated RMSNorm.
На крупномасштабном датасете «Яндекс Музыки» гибридный энкодер, в котором блоки self-attention (SA) и GBLA чередуются в соотношении 1:2 — один блок SA, за которым следуют два блока GBLA, — достигает качества двунаправленного self-attention.
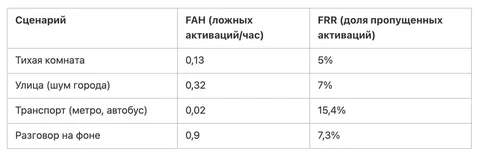
Бонусом держите фото с места событий и фотографию крутого зубастого участника конференции.
#YaSIGIR26
ML Underhood


В эти дни в Мельбурне проходит конференция по исследованиям и разработке информационного поиска. И мы уже там, чтобы посмотреть (и вам показать) интересное, а также представить собственную работу — Gated Bidirectional Linear Attention for Generative Retrieval.
В рекомендательных системах generative retrieval обычно строится по схеме «энкодер–декодер». Энкодер обрабатывает историю взаимодействий пользователя, после чего авторегрессионный декодер генерирует рекомендуемые объекты. В крупных стриминговых сервисах активные пользователи со временем накапливают очень длинные истории. По мере их роста энкодер становится одним из основных узких мест с точки зрения задержки, поскольку вычислительная сложность внимания с softmax квадратично зависит от длины последовательности.
В статье предлагают Gated Bidirectional Linear Attention (GBLA) — слой двунаправленного аттеншена с линейной вычислительной сложностью, который расширяет линейное внимание тремя компонентами: локальным каузальным смешиванием с помощью Conv1D, гейтингом ключей на уровне последовательности для мягкого забывания и выходным слоем gated RMSNorm.
На крупномасштабном датасете «Яндекс Музыки» гибридный энкодер, в котором блоки self-attention (SA) и GBLA чередуются в соотношении 1:2 — один блок SA, за которым следуют два блока GBLA, — достигает качества двунаправленного self-attention.
Бонусом держите фото с места событий и фотографию крутого зубастого участника конференции.
#YaSIGIR26
ML Underhood
861 просмотров · 21 реакций
Открыть в Telegram · Открыть пост на сайте